


Лексический анализ
01.01.2007
7. Лексический анализ
ВВЕДЕНИЕ В последней главе я оставил вас с компилятором который должен почти работать, за исключением того, что мы все еще ограничены одно-символьными токенами. Цель этого урока состоит в том, чтобы избавиться от этого ограничения раз и навсегда. Это означает, что мы должны иметь дело с концепцией лексического анализатора (сканера). Возможно я должен упомянуть, почему нам вообще нужен лексический анализатор... в конце концов до настоящего времени мы были способны хорошо справляться и без него даже когда мы предусмотрели много символьные токены. Единственная причина, на самом деле, имеет отношение к ключевым словам. Это факт компьютерной жизни, что синтаксис ключевого слова имеет ту же самую форму, что и синтаксис любого другого идентификатора. Мы не можем сказать пока не получим полное слово действительно ли это ключевое слово. К примеру переменная IFILE и ключевое слово IF выглядят просто одинаковыми до тех пор, пока вы не получите третий символ. В примерах до настоящего времени мы были всегда способны принять решение, основанное на первом символе токена, но это больше невозможно когда присутствуют ключевые слова. Нам необходимо знать, что данная строка является ключевым словом до того, как мы начнем ее обрабатывать. И именно поэтому нам нужен сканер. На последнем уроке я также пообещал, что мы могли бы предусмотреть нормальные токены без глобальных изменений того, что мы уже сделали. Я не солгал... мы можем, как вы увидите позднее. Но каждый раз, когда я намеревался встроить эти элементы в синтаксический анализатор, который мы уже построили, у меня возникали плохие чувства в отношении их. Все это слишком походило на временную меру. В конце концов я выяснил причину проблемы: я установил программу лексического анализа не объяснив вам вначале все о лексическом анализе, и какие есть альтернативы. До настоящего времени я старательно избегал давать вам много теории и, конечно, альтернативные варианты. Я обычно не воспринимаю хорошо учебники которые дают двадцать пять различных способов сделать что-то, но никаких сведений о том, какой способ лучше всего вам подходит. Я попытался избежать этой ловушки, просто показав вам один способ, который работает. Но это важная область. Хотя лексический анализатор едва ли является наиболее захватывающей частью компилятора он часто имеет наиболее глубокое влияние на общее восприятие языка так как эта часть наиболее близка пользователю. Я придумал специфическую структуру сканера, который будет использоваться с KISS. Она соответствует восприятию, которое я хочу от этого языка. Но она может совсем не работать для языка, который придумаете вы, поэтому в этом единственном случае я чувствую, что вам важно знать ваши возможности. Поэтому я собираюсь снова отклониться от своего обычного распорядка. На этом уроке мы заберемся гораздо глубже, чем обычно, в базовую теорию языков и грамматик. Я также буду говорить о других областях кроме компиляторов в которых лексических анализ играет важную роль. В заключение я покажу вам некоторые альтернативы для структуры лексического анализатора. Тогда и только тогда мы возвратимся к нашему синтаксическому анализатору из последней главы. Потерпите... я думаю вы найдете, что это стоит ожидания. Фактически, так как сканеры имеют множество применений вне компиляторов, вы сможете легко убедиться, что это будет наиболее полезный для вас урок. ЛЕКСИЧЕСКИЙ АНАЛИЗ Лексический анализ - это процесс сканирования потока входных символов и разделения его на строки, называемые лексемами. Большинство книг по компиляторам начинаются с этого и посвящают несколько глав обсуждению различных методов построения сканеров. Такой подход имеет свое место, но, как вы уже видели, существуют множество вещей, которые вы можете сделать даже никогда не обращавшись к этому вопросу, и, фактически, сканер, который мы здесь закончим, не очень будет напоминать то, что эти тексты описывают. Причина? Теория компиляторов и, следовательно, программы, следующие из нее, должны работать с большинством общих правил синтаксического анализа. Мы же не делаем этого. В реальном мире возможно определить синтаксис языка таким образом, что будет достаточно довольно простого сканера. И как всегда KISS - наш девиз. Как правило, лексический анализатор создается как отдельная часть компилятора, так что синтаксический анализатор по существу видит только поток входных лексем. Теоретически нет необходимости отделять эту функцию от остальной части синтаксического анализатора. Имеется только один набор синтаксических уравнений, который определяет весь язык, поэтому теоретически мы могли бы написать весь анализатор в одном модуле. Зачем необходимо разделение? Ответ имеет и теоретическую и практическую основы. В 1956 Ноам Хомский определил "Иерархию Хомского" для грамматик. Вот они:| · | Тип 0. Неограниченные (например Английский язык) |
| · | Тип 1. Контекстно-зависимые |
| · | Тип 2. Контекстно-свободные |
| · | Тип 3. Регулярные. |
begin
IsAlNum := IsAlpha(c) or IsDigit(c);
end;
Используя ее, давайте напишем следующие две подпрограммы, которые очень похожи на те, которые мы использовали раньше:
{ Get an Identifier }
function GetName: string;
var x: string[8];
begin
x := '';
if not IsAlpha(Look) then Expected('Name');
while IsAlNum(Look) do begin
x := x + UpCase(Look);
GetChar;
end;
GetName := x;
end;
{ Get a Number }
function GetNum: string;
var x: string[16];
begin
x := '';
if not IsDigit(Look) then Expected('Integer');
while IsDigit(Look) do begin
x := x + Look;
GetChar;
end;
GetNum := x;
end;
(Заметьте, что эта версия GetNum возвращает строку, а не целое число, как прежде).
Вы можете легко проверить что эти подпрограммы работают, вызвав их из основной программы:
WriteLn(GetName);
Эта программа выведет любое допустимое набранное имя (максимум восемь знаков, потому что мы так сказали GetName). Она отвергнет что-либо другое.
Аналогично проверьте другую подпрограмму.
ПРОБЕЛ
Раньше мы также работали с вложенными пробелами, используя две подпрограммы IsWhite и SkipWhite. Удостоверьтесь, что эти подпрограммы есть в вашей текущей версии Cradle и добавьте строку:
SkipWhite;
в конец GetName и GetNum.
Теперь давайте определим новую процедуру:
{ Lexical Scanner }
Function Scan: string;
begin
if IsAlpha(Look) then
Scan := GetName
else if IsDigit(Look) then
Scan := GetNum
else begin
Scan := Look;
GetChar;
end;
SkipWhite;
end;
Мы можем вызвать ее из новой основной программы:
{ Main Program }
begin
Init;
repeat
Token := Scan;
writeln(Token);
until Token = CR;
end.
(Вы должны добавить описание строки Token в начало программы. Сделайте ее любой удобной длины, скажем 16 символов).
Теперь запустите программу. Заметьте, что входная строка действительно разделяется на отдельные токены.
КОНЕЧНЫЕ АВТОМАТЫ
Подпрограмма анализа типа GetName действительно реализует конечный автомат. Состояние неявно в текущей позиции в коде. Очень полезным приемом для визуализации того, что происходит, является синтаксическая диаграмма или "railroad-track" диаграмма. Немного трудно нарисовать их в этой среде, поэтому я буду использовать их очень экономно, но фигура ниже должна дать вам идею:
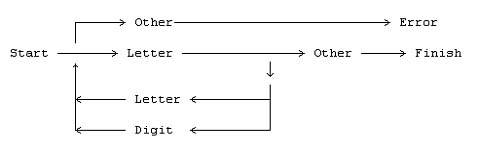 Как вы можете видеть, эта диаграмма показывает логические потоки по мере чтения символов. Начинается все, конечно, с состояния "start" и заканчивается когда найден символ, отличный от алфавитно-цифрового. Если первый символ не буква, происходит ошибка. Иначе автомат продолжит выполнение цикла до тех пор, пока не будет найден конечный разделитель.
Заметьте, что в любой точке потока наша позиция полностью зависит от предыдущей истории входных символов. В этой точке предпринимаемые действия зависят только от текущего состояния плюс текущий входной символ. Это и есть то, что образует конечный автомат.
Из-за сложностей представления "railroad-track" диаграмм в этой среде я буду продолжать придерживаться с этого времени синтаксических уравнений. Но я настоятельно рекомендую вам диаграммы для всего, что включает синтаксический анализ. После небольшой практики вы можете начать видеть, как написать синтаксический анализатор непосредственно из диаграммы. Параллельные пути кодируются в контролирующие действия (с помощью операторов IF или CASE), последовательные пути - в последовательные вызовы. Это почти как работа по схеме.
Мы даже не обсудили SkipWhite, которая была представлена раньше, но это также простой конечный автомат, как и GetNum. Так же как и их родительская процедура Scan. Маленькие автоматы образуют большие автоматы.
Интересная вещь, на которую я хотел бы чтобы вы обратили внимание это то, как безболезненно такой неявный подход создает эти конечные автоматы. Я лично предпочитаю его таблично управляемому методу. Он также получает маленькие, компактные и быстрые сканеры.
НОВЫЕ СТРОКИ
Продвигаясь прямо вперед, давайте модифицируем наш сканер для поддержки более чем одной строки. Как я упомянул последний раз, наиболее простой способ сделать это - просто обработать символы новой строки, возврат каретки и перевод строки, как незаполненное пространство. Фактически это способ, используемый подпрограммой iswhite из стандартной библиотеки C. Прежде мы не этого делали. Я хотел бы сделать это теперь, чтобы вы могли почувствовать результат.
Чтобы сделать это просто измените единственную выполнимую строку в IsWhite:
IsWhite := c in [' ', TAB, CR, LF];
Мы должны дать основной программы новое условие останова, так как она никогда не увидит CR. Давайте просто используем:
until Token = '.';
ОК, откомпилируйте эту программу и запустите ее. Попробуйте пару строк, завершаемых точкой. Я использовал:
now is the time
for all good men.
Эй, что случилось? Когда я набрал это, я не получил последний токен, точку. Программа не остановилась. Более того, когда я нажал клавишу 'enter' несколько раз, я все равно не получил точку.
Если вы все еще не можете выбраться из вашей программы, вы обнаружите, что набор точки в новой строке прервет ее.
Что здесь происходит? Ответ в том, что мы зависаем в SkipWhite. Короткий осмотр этой подпрограммы покажет, что пока мы печатаем пустые строки, мы просто продолжаем выполнение цикла. После того, как SkipWhite встречает LF, он пытается выполнить GetChar. Но так как входной буфер теперь пуст, оператор чтения в GetChar настаивает на наличии другой строки. Процедура Scan получает завершающую точку, все правильно, но она вызывает SkipWhite и SkipWhite не возвращается до тех пор, пока не получит непустую строку.
Такое поведение не настолько плохое, как кажется. В настоящем компиляторе мы читали бы символы из входного файла вместо консоли и пока мы имеем какую-то процедуру для работы с концом файла, все получится ОК. Но для чтения данных с консоли такое поведение слишком причудливое. Суть в том, что соглашение C/Unix просто не совместимо со структурой нашего анализатора, который запрашивает предсказывающий символ. Код, который мастера из Bell реализовали, не использует это соглашение, поэтому они нуждаются в 'ungetc'.
ОК, давайте исправим проблему. Чтобы сделать это, мы должны возвратиться к старому определению IsWhite (удалите символы CR и LF) и используйте процедуру Fin, которую я представил в последний раз. Если ее нет в вашей текущей версии Cradle, поместите ее там.
Также измените основную программу следующим образом:
Как вы можете видеть, эта диаграмма показывает логические потоки по мере чтения символов. Начинается все, конечно, с состояния "start" и заканчивается когда найден символ, отличный от алфавитно-цифрового. Если первый символ не буква, происходит ошибка. Иначе автомат продолжит выполнение цикла до тех пор, пока не будет найден конечный разделитель.
Заметьте, что в любой точке потока наша позиция полностью зависит от предыдущей истории входных символов. В этой точке предпринимаемые действия зависят только от текущего состояния плюс текущий входной символ. Это и есть то, что образует конечный автомат.
Из-за сложностей представления "railroad-track" диаграмм в этой среде я буду продолжать придерживаться с этого времени синтаксических уравнений. Но я настоятельно рекомендую вам диаграммы для всего, что включает синтаксический анализ. После небольшой практики вы можете начать видеть, как написать синтаксический анализатор непосредственно из диаграммы. Параллельные пути кодируются в контролирующие действия (с помощью операторов IF или CASE), последовательные пути - в последовательные вызовы. Это почти как работа по схеме.
Мы даже не обсудили SkipWhite, которая была представлена раньше, но это также простой конечный автомат, как и GetNum. Так же как и их родительская процедура Scan. Маленькие автоматы образуют большие автоматы.
Интересная вещь, на которую я хотел бы чтобы вы обратили внимание это то, как безболезненно такой неявный подход создает эти конечные автоматы. Я лично предпочитаю его таблично управляемому методу. Он также получает маленькие, компактные и быстрые сканеры.
НОВЫЕ СТРОКИ
Продвигаясь прямо вперед, давайте модифицируем наш сканер для поддержки более чем одной строки. Как я упомянул последний раз, наиболее простой способ сделать это - просто обработать символы новой строки, возврат каретки и перевод строки, как незаполненное пространство. Фактически это способ, используемый подпрограммой iswhite из стандартной библиотеки C. Прежде мы не этого делали. Я хотел бы сделать это теперь, чтобы вы могли почувствовать результат.
Чтобы сделать это просто измените единственную выполнимую строку в IsWhite:
IsWhite := c in [' ', TAB, CR, LF];
Мы должны дать основной программы новое условие останова, так как она никогда не увидит CR. Давайте просто используем:
until Token = '.';
ОК, откомпилируйте эту программу и запустите ее. Попробуйте пару строк, завершаемых точкой. Я использовал:
now is the time
for all good men.
Эй, что случилось? Когда я набрал это, я не получил последний токен, точку. Программа не остановилась. Более того, когда я нажал клавишу 'enter' несколько раз, я все равно не получил точку.
Если вы все еще не можете выбраться из вашей программы, вы обнаружите, что набор точки в новой строке прервет ее.
Что здесь происходит? Ответ в том, что мы зависаем в SkipWhite. Короткий осмотр этой подпрограммы покажет, что пока мы печатаем пустые строки, мы просто продолжаем выполнение цикла. После того, как SkipWhite встречает LF, он пытается выполнить GetChar. Но так как входной буфер теперь пуст, оператор чтения в GetChar настаивает на наличии другой строки. Процедура Scan получает завершающую точку, все правильно, но она вызывает SkipWhite и SkipWhite не возвращается до тех пор, пока не получит непустую строку.
Такое поведение не настолько плохое, как кажется. В настоящем компиляторе мы читали бы символы из входного файла вместо консоли и пока мы имеем какую-то процедуру для работы с концом файла, все получится ОК. Но для чтения данных с консоли такое поведение слишком причудливое. Суть в том, что соглашение C/Unix просто не совместимо со структурой нашего анализатора, который запрашивает предсказывающий символ. Код, который мастера из Bell реализовали, не использует это соглашение, поэтому они нуждаются в 'ungetc'.
ОК, давайте исправим проблему. Чтобы сделать это, мы должны возвратиться к старому определению IsWhite (удалите символы CR и LF) и используйте процедуру Fin, которую я представил в последний раз. Если ее нет в вашей текущей версии Cradle, поместите ее там.
Также измените основную программу следующим образом:
{ Main Program }
begin
Init;
repeat
Token := Scan;
writeln(Token);
if Token = CR then Fin;
until Token = '.';
end.
Обратите внимание на "охраняющую" проверку, предшествующую вызову Fin. Это то, что заставляет все это работать, и проверяет, то мы не пытаемся прочитать строку дальше.
Сейчас испытайте этот код. Я думаю он понравится вам больше.
Если вы обратитесь к коду, который мы написали в последней главе, вы обнаружите, что я расставил вызовы Fin по всему коду, где прерывание строки было бы уместным. Это одна из тех областей, которые действительно влияют на восприятие, о котором я упомянул. В этой точке я должен убедить вас поэкспериментировать с различными способами организациями и посмотреть, как вам это понравится. Если вы хотите, чтобы ваш язык был по настоящему свободного стиля, тогда новые строки должны быть прозрачны. В этом случае наилучшим подходом было бы поместить следующие строки в начале Scan:
while Look = CR do
Fin;
Если, с другой стороны, вам нужен строчно-ориентированный язык подобный Ассемблеру, BASIC или FORTRAN (или даже Ada... заметьте, что он имеет комментарии, завершаемые новой строкой), тогда вам необходимо, чтобы Scan возвращал CR как токены. Он также должен съедать завершающие LF. Лучший способ сделать - использовать эту строку в самом начале Scan:
if Look = LF then Fin;
Для других соглашений вы будете должны использовать другие способы организации. В моем примере на последнем уроке я разрешил новые строки только в определенных местах, поэтому я занял какое-то промежуточное положение. В остальных частях этих занятий я буду выбирать такие способы обработки новых строк какие мне понравятся, но я хочу, чтобы вы знали, как выбрать для себя другой путь.
ОПЕРАТОРЫ
Мы могли бы сейчас остановиться и иметь в своем распоряжении довольно полезный сканер. В тех фрагментах KISS, которые мы построили, единственными токенами, состоящими из нескольких символов, являются идентификаторы и числа. Все операторы были одно-символьными. Единственное исключение, которое я могу придумать - это операторы отношений "<=", ">=" и "<>", но они могут быть обработаны как особые случаи.
Однако другие языки имеют много символьные операторы такие как ":=" в Паскале или "++" и ">>" в C. Хотя пока нам и не нужны много символьные операторы, было бы хорошо знать как получить их в случае необходимости.
Само собой разумеется, что мы можем обрабатывать операторы точно таким же способом, что и другие токены. Давайте начнем с подпрограммы распознавания:
{ Recognize Any Operator }
function IsOp(c: char): boolean;
begin
IsOp := c in ['+', '-', '*', '/', '<', '>', ':', '='];
end;
Важно заметить, что мы не должны включать в этот список каждый возможный оператор. К примеру круглые скобки не включены, так же как и завершающая точка. Текущая версия Scan и так хорошо поддерживает одно-символьные операторы. Список выше включает только те символы, которые могут появиться в много символьных операторах. (Для конкретных языков список конечно всегда может быть отредактирован).
Теперь давайте изменим Scan следующим образом:
{ Lexical Scanner }
Function Scan: string;
begin
while Look = CR do
Fin;
if IsAlpha(Look) then
Scan := GetName
else if IsDigit(Look) then
Scan := GetNum
else if IsOp(Look) then
Scan := GetOp
else begin
Scan := Look;
GetChar;
end;
SkipWhite;
end;
Теперь испытайте программу. Вы убедитесь, что любые фрагменты кода, которые вы захотите бросить в нее будут аккуратно разложены на индивидуальные токены. СПИСКИ, ЗАПЯТЫЕ И КОМАНДНЫЕ СТРОКИ. Прежде чем возвратиться к основной цели нашего обучения, я хотел бы немного выступить. Сколько раз вы работали с программой или операционной системой, которая имела жесткие правила того, как вы должны разделять элементы в списке? (Попробую, последний раз вы использовали MS DOS!). Некоторые программы требуют пробелов как разделителей, некоторые требуют запятые. Хуже всего, что некоторые требуют и того и другого в разных местах. Большинство довольно неумолимы к нарушениям их правил. Я думаю, это непростительно. Слишком просто написать синтаксически анализатор, который поддерживает и пробелы и запятые гибким способом. Рассмотрите следующую процедуру:
{ Skip Over a Comma }
procedure SkipComma;
begin
SkipWhite;
if Look = ',' then begin
GetChar;
SkipWhite;
end;
end;
Эта процедура из восьми строк пропустит разделитель, состоящий из любого числа (включая ноль) пробелов, с нулем или одной запятой, вложенной в строку.
Временно измените вызов SkipWhite в Scan на вызов SkipComma и попробуйте ввести какие-нибудь списки. Хорошо работает, да? Разве вы не хотите, чтобы больше создателей программ знало о SkipComma?
К слову сказать, я обнаружил, что добавление эквивалента SkipComma в мою программу на ассемблере для Z80 заняло всего шесть дополнительных байт кода. Даже на 64K машинах это не слишком большая цена за дружелюбие к пользователю.
Я думаю вы можете видеть к чему я клоню. Даже если вы в своей жизни не написали ни одной строчки кода для компилятора, в каждой программе существуют места, где вы можете использовать понятие синтаксического анализа. Любая программа, которая обрабатывает командные строки, нуждается в нем. Фактически, если вы подумаете немного об этом, вы придете к заключению, что всякий раз, когда вы пишете программу, обрабатывающую ввод пользователя, вы определяете язык. Люди общаются с помощью языков и неявный синтаксис в вашей программе определяет этот язык. Настоящий вопрос: вы собираетесь определять его преднамеренно и явно, или просто позволите существовать независимо от того, как программа завершает синтаксический анализ?
Я утверждаю, что у вас будет лучший, более дружественный интерфейс если вы потратите время на то, чтобы определить синтаксис явно. Запишите синтаксические уравнения или нарисуйте "railroad-track" диаграммы и закодируйте синтаксический анализатор используя методы, которые я показал вам здесь. Вы получите более хорошую программу и ее будет проще писать, в придачу.
СТАНОВИТСЯ ИНТЕРЕСНЕЙ
Хорошо, сейчас мы имеем довольно хороший лексический анализатор, который разбивает входной поток на лексемы. Мы могли бы использовать его как есть и иметь полезный компилятор. Но есть некоторые другие аспекты лексического анализа, которые мы должны охватить.
Особенно следует рассмотреть (вздрогните) эффективность. Помните, когда мы работали с одно-символьными токенами, каждой проверкой было сравнение одного символа Look с байтовой константой. Мы также использовали в основном оператор Case.
С много символьными лексемами, возвращаемыми Scan, все эти проверки становятся сравнением строк. Гораздо медленнее. И не только медленнее но и неудобней, так как в Паскале не существует строкового эквивалента оператора Case. Особенно расточительным кажется проверять то что состоит из одного символа... "=", "+" и другие операторы... используя сравнение строк.
Сравнение строк не является невозможным. Рон Кейн использовал этот подход при написании Small C. Так как мы придерживаемся принципа KISS мы были бы оправданы согласившись с этим подходом. Но тогда я не смог бы рассказать вам об одном из ключевых методов, используемых в "настоящих" компиляторах.
Вы должны запомнить: лексический анализатор будет вызываться часто! Фактически один раз для каждой лексемы во всей исходной программе. Эксперименты показали, что средний компилятор тратит где-то от 20 до 40 процентов своего времени на подпрограммах лексического анализа. Если существовало когда-либо место, где эффективность заслуживает пристального рассмотрения, то это оно.
По этой причине большинство создателей компиляторов заставляют лексический анализатор выполнять немного больше работы, "токенизируя" входной поток. Идея состоит в том, чтобы сравнивать каждую лексему со списком допустимых ключевых слов и операторов и возвращать уникальный код для каждой распознанной. В случае обычного имени переменной или числа мы просто возвращаем код, который говорит, к какому типу лексем они относятся и сохраняем где-нибудь текущую строку.
Первое, что нам нужно - это способ идентификации ключевых слов. Мы всегда можем сделать это с помощью последовательных проверок IF, но несомненно было бы хорошо, если бы мы имели универсальную подпрограмму, которая могла бы сравнивать данную строку с таблицей ключевых слов. (Между прочим, позднее нам понадобится такая же подпрограмма для работы с таблицей идентификаторов). Это обычно выявляет проблему Паскаля, потому что стандартный Паскаль не имеет массивов переменной длины. Это настоящая головная боль - объявлять различные подпрограммы поиска для каждой таблицы. Стандартный Паскаль также не позволяет инициализировать массивы, поэтому вам придется видеть код типа:
Table[1] := 'IF'; Table[2] := 'ELSE';
.
.
Table[n] := 'END'; что может получиться довольно длинным если есть много ключевых слов. К счастью Turbo Pascal 4.0 имеет расширения, которые устраняют обе эти проблемы. Массивы-константы могут быть объявлены с использованием средства TP "типизированные константы" а переменные размерности могут быть поддержаны с помощью Си-подобных расширений для указателей. Сначала, измените ваши объявления подобным образом:
{ Type Declarations }
type Symbol = string[8];
SymTab = array[1..1000] of Symbol;
TabPtr = ^SymTab;
(Размерность, использованная в SymTab не настоящая... память не распределяется непосредственно этим объявлением, а размерность должна быть только "достаточно большой")
Затем, сразу после этих объявлений, добавьте следующее:
{ Definition of Keywords and Token Types }
const KWlist: array [1..4] of Symbol =
('IF', 'ELSE', 'ENDIF', 'END');
Затем, вставьте следующую новую функцию:
{ Table Lookup }
{ If the input string matches a table entry, return the entry
index. If not, return a zero. }
function Lookup(T: TabPtr; s: string; n: integer): integer;
var i: integer;
found: boolean;
begin
found := false;
i := n;
while (i > 0) and not found do
if s = T^[i] then
found := true
else
dec(i);
Lookup := i;
end;
Чтобы проверить ее вы можете временно изменить основную программу следующим образом:
{ Main Program }
begin
ReadLn(Token);
WriteLn(Lookup(Addr(KWList), Token, 4));
end.
Обратите внимание как вызывается Lookup: функция Addr устанавливает указатель на KWList, который передается в Lookup. ОК, испытайте ее. Так как здесь мы пропускаем Scan, для получения соответствия вы должны набирать ключевые слова в верхнем регистре. Теперь, когда мы можем распознавать ключевые слова, далее необходимо договориться о возвращаемых для них кодах. Итак, какие кода мы должны возвращать? В действительности есть только два приемлемых варианта. Это похоже на идеальное применения перечисляемого типа Паскаля. К примеру, вы можете определить что-то типа SymType = (IfSym, ElseSym, EndifSym, EndSym, Ident, Number, Operator); и договориться возвращать переменную этого типа. Давайте попробуем это. Вставьте строку выше в описание типов. Теперь добавьте два описания переменных: Token: Symtype; { Current Token } Value: String[16]; { String Token of Look } Измените сканер так:
{ Lexical Scanner }
procedure Scan;
var k: integer;
begin
while Look = CR do
Fin;
if IsAlpha(Look) then begin
Value := GetName;
k := Lookup(Addr(KWlist), Value, 4);
if k = 0 then
Token := Ident
else
Token := SymType(k - 1);
end
else if IsDigit(Look) then begin
Value := GetNum;
Token := Number;
end
else if IsOp(Look) then begin
Value := GetOp;
Token := Operator;
end
else begin
Value := Look;
Token := Operator;
GetChar;
end;
SkipWhite;
end;
(Заметьте, что Scan сейчас стала процедурой а не функцией).
{ Main Program }
begin
Init;
repeat
Scan;
case Token of
Ident: write('Ident ');
Number: Write('Number ');
Operator: Write('Operator ');
IfSym, ElseSym, EndifSym, EndSym: Write('Keyword ');
end;
Writeln(Value);
until Token = EndSym;
end.
Наконец, измените основную программу:
Мы заменили строку Token, используемую раньше, на перечислимый тип. Scan возвращает тип в переменной Token и возвращает саму строку в новой переменной Value. ОК, откомпилируйте программу и погоняйте ее. Если все работает, вы должны увидеть, что теперь мы распознаем ключевые слова. Теперь у нас все работает правильно, и было легко сгенерировать это из того, что мы имели раньше. Однако, она все равно кажется мне немного "перегруженной". Мы можем ее немного упростить, позволив GetName, GetNum, GetOp и Scan работать с глобальными переменными Token и Value, вследствие этого удаляя их локальные копии. Кажется немного умней было бы переместить просмотр таблицы в GetName. Тогда новая форма для этих четырех процедур будет такой:
{ Get an Identifier }
procedure GetName;
var k: integer;
begin
Value := '';
if not IsAlpha(Look) then Expected('Name');
while IsAlNum(Look) do begin
Value := Value + UpCase(Look);
GetChar;
end;
k := Lookup(Addr(KWlist), Value, 4);
if k = 0 then
Token := Ident
else
Token := SymType(k-1);
end;
{ Get a Number }
procedure GetNum;
begin
Value := '';
if not IsDigit(Look) then Expected('Integer');
while IsDigit(Look) do begin
Value := Value + Look;
GetChar;
end;
Token := Number;
end;
{ Get an Operator }
procedure GetOp;
begin
Value := '';
if not IsOp(Look) then Expected('Operator');
while IsOp(Look) do begin
Value := Value + Look;
GetChar;
end;
Token := Operator;
end;
{ Lexical Scanner }
procedure Scan;
var k: integer;
begin
while Look = CR do
Fin;
if IsAlpha(Look) then
GetName
else if IsDigit(Look) then
GetNum
else if IsOp(Look) then
GetOp
else begin
Value := Look;
Token := Operator;
GetChar;
end;
SkipWhite;
end;
ВОЗВРАЩЕНИЕ СИМВОЛА По существу, все сканеры, которые я когда-либо видел, и которые написаны на Паскале, использовали механизм перечислимых типов, который я только что описал. Это конечно работающий механизм, но он не кажется мне самым простым подходом. Прежде всего, список возможных типов символов может получиться довольно длинным. Здесь я использовал только один символ "Operator" для обозначения всех операторов, но я видел другие проекты, в которых фактически возвращаются различные кода для каждого. Существует, конечно, другой простой тип, который может быть возвращен как код: символ. Вместо возвращения значения "Operator" для знака "+", что неправильного в том, чтобы просто возвращать сам символ? Символ - такая же хорошая переменная для кодирования различных типов лексем, она легко может быть использована в операторах Case, и это гораздо проще набрать. Что может быть проще? Кроме того, мы уже имели опыт с идеей кодировать ключевые слова как одиночные символы. Наши предыдущие программы уже написаны таким способом, так что использование этого метода минимизирует изменения того, что мы уже сделали. Некоторые из вас могут почувствовать, что идея с возвращение символьных кодов слишком детская. Я должен допустить, что она становится немного неуклюжей для операторов типа "<=". Если вы хотите остаться с перечислимыми типами, хорошо. Для остальных я хотел бы показать как изменить то, что мы сделали выше, для поддержки такого подхода. Во-первых, сейчас вы можете удалить объявление типа SymType... он нам больше не понадобится. И вы можете изменить тип Token в char. Затем, чтобы заменить SymType, добавьте следующую константу: const KWcode: string[5] = 'xilee'; (Я буду кодировать все идентификаторы одиночным символом 'x'). Наконец измените Scan и его родственников следующим образом:
{ Get an Identifier }
procedure GetName;
begin
Value := '';
if not IsAlpha(Look) then Expected('Name');
while IsAlNum(Look) do begin
Value := Value + UpCase(Look);
GetChar;
end;
Token := KWcode[Lookup(Addr(KWlist), Value, 4) + 1];
end;
{ Get a Number }
procedure GetNum;
begin
Value := '';
if not IsDigit(Look) then Expected('Integer');
while IsDigit(Look) do begin
Value := Value + Look;
GetChar;
end;
Token := '#';
end;
{ Get an Operator }
procedure GetOp;
begin
Value := '';
if not IsOp(Look) then Expected('Operator');
while IsOp(Look) do begin
Value := Value + Look;
GetChar;
end;
if Length(Value) = 1 then
Token := Value[1]
else
Token := '?';
end;
{ Lexical Scanner }
procedure Scan;
var k: integer;
begin
while Look = CR do
Fin;
if IsAlpha(Look) then
GetName
else if IsDigit(Look) then
GetNum
else if IsOp(Look) then begin
GetOp
else begin
Value := Look;
Token := '?';
GetChar;
end;
SkipWhite;
end;
{ Main Program }
begin
Init;
repeat
Scan;
case Token of
'x': write('Ident ');
'#': Write('Number ');
'i', 'l', 'e': Write('Keyword ');
else Write('Operator ');
end;
Writeln(Value);
until Value = 'END';
end.
Эта программа должна работать также как и предыдущая версия. Небольшое различие в структуре, может быть, но она кажется мне более простой.
РАСПРЕДЕЛЕННЫЕ СКАНЕРЫ ПРОТИВ ЦЕНТРАЛИЗОВАННЫХ
Структура лексического анализатора, которую я только что вам показал, весьма стандартна и примерно 99% всех компиляторов используют что-то очень близкое к ней. Это, однако, не единственно возможная структура, или даже не всегда самая лучшая.
Проблема со стандартным подходом состоит в том, что сканер не имеет никаких сведений о контексте. Например, он не может различить оператор присваивания "=" и оператор отношения "=" (возможно именно поэтому и C и Паскаль используют для них различные строки). Все, что сканер может сделать, это передать оператор синтаксическому анализатору, который может точно сказать исходя из контекста, какой это оператор. Точно так же, ключевое слово "IF" не может быть посредине арифметического выражения, но если ему случится оказаться там, сканер не увидит в этом никакой проблемы и возвратит его синтаксическому анализатору, правильно закодировав как "IF".
С таким подходом, мы в действительности не используем всю информацию, имеющуюся в нашем распоряжении. В середине выражения, например синтаксический анализатор "знает", что нет нужды искать ключевое слово, но он не имеет никакой возможности сказать это сканеру. Так что сканер продолжает делать это. Это, конечно, замедляет компиляцию.
В настоящих компиляторах проектировщики часто принимают меры для передачи подробной информации между сканером и парсером, только чтобы избежать такого рода проблем. Но это может быть неуклюже и, конечно, уничтожит часть модульности в структуре компилятора.
Альтернативой является поиск какого-то способа для использования контекстной информации, которая исходит из знания того, где мы находимся в синтаксическом анализаторе. Это возвращает нас обратно к понятию распределенного сканера, в котором различные части сканера вызываются в зависимости от контекста.
В языке KISS, как и большинстве языков, ключевые слова появляются только в начале утверждения. В таких местах, как выражения они запрещены. Также, с одним небольшим исключением (много символьные операторы отношений), которое легко обрабатывается, все операторы одно-символьны, что означает, что нам совсем не нужен GetOp.
Так что, оказывается, даже с много символьными токенами мы все еще можем всегда точно определить вид лексемы исходя из текущего предсказывающего символа, исключая самое начало утверждения.
Даже в этой точке, единственным видом лексемы, который мы можем принять, является идентификатор. Нам необходимо только определить, является ли этот идентификатор ключевым словом или левой частью оператора присваивания.
Тогда мы заканчиваем все еще нуждаясь только в GetName и GetNum, которые используются так же, как мы использовали их в ранних главах.
Сначала вам может показаться, что это шаг назад и довольно примитивный способ. Фактически же, это усовершенствование классического сканера, так как мы используем подпрограммы сканирования только там, где они действительно нужны. В тех местах, где ключевые слова не разрешены, мы не замедляем компиляцию, ища их.
ОБЪЕДИНЕНИЕ СКАНЕРА И ПАРСЕРА
Теперь, когда мы охватили всю теорию и общие аспекты лексического анализа, я наконец готов подкрепит свое заявление о том, что мы можем приспособить много символьные токены с минимальными изменениями в нашей предыдущей работе. Для краткости и простоты я ограничу сам себя подмножеством того, что мы сделали ранее: я разрешу только одну управляющую конструкцию (IF) и никаких булевых выражений. Этого достаточно для демонстрации синтаксического анализа и ключевых слов и выражений. Расширение до полного набора конструкций должно быть довольно очевидно из того, что мы уже сделали.
Все элементы программы для синтаксического анализа этого подмножества с использованием одно-символьных токенов уже существуют в наших предыдущих программах. Я построил ее осторожно скопировав эти файлы, но я не посмею попробовать провести вас через этот процесс. Вместо этого, во избежание беспорядка, вся программа показана ниже:
program KISS;
{ Constant Declarations }
const TAB = ^I;
CR = ^M;
LF = ^J;
{ Type Declarations }
type Symbol = string[8];
SymTab = array[1..1000] of Symbol;
TabPtr = ^SymTab;
{ Variable Declarations }
var Look : char; { Lookahead Character }
Lcount: integer; { Label Counter }
{ Read New Character From Input Stream }
procedure GetChar;
begin
Read(Look);
end;
{ Report an Error }
procedure Error(s: string);
begin
WriteLn;
WriteLn(^G, 'Error: ', s, '.');
end;
{ Report Error and Halt }
procedure Abort(s: string);
begin
Error(s);
Halt;
end;
{ Report What Was Expected }
procedure Expected(s: string);
begin
Abort(s + ' Expected');
end;
{ Recognize an Alpha Character }
function IsAlpha(c: char): boolean;
begin
IsAlpha := UpCase(c) in ['A'..'Z'];
end;
{ Recognize a Decimal Digit }
function IsDigit(c: char): boolean;
begin
IsDigit := c in ['0'..'9'];
end;
{ Recognize an AlphaNumeric Character }
function IsAlNum(c: char): boolean;
begin
IsAlNum := IsAlpha(c) or IsDigit(c);
end;
{ Recognize an Addop }
function IsAddop(c: char): boolean;
begin
IsAddop := c in ['+', '-'];
end;
{ Recognize a Mulop }
function IsMulop(c: char): boolean;
begin
IsMulop := c in ['*', '/'];
end;
{ Recognize White Space }
function IsWhite(c: char): boolean;
begin
IsWhite := c in [' ', TAB];
end;
{ Skip Over Leading White Space }
procedure SkipWhite;
begin
while IsWhite(Look) do
GetChar;
end;
{ Match a Specific Input Character }
procedure Match(x: char);
begin
if Look <> x then Expected('''' + x + '''');
GetChar;
SkipWhite;
end;
{ Skip a CRLF }
procedure Fin;
begin
if Look = CR then GetChar;
if Look = LF then GetChar;
SkipWhite;
end;
{ Get an Identifier }
function GetName: char;
begin
while Look = CR do
Fin;
if not IsAlpha(Look) then Expected('Name');
Getname := UpCase(Look);
GetChar;
SkipWhite;
end;
{ Get a Number }
function GetNum: char;
begin
if not IsDigit(Look) then Expected('Integer');
GetNum := Look;
GetChar;
SkipWhite;
end;
{ Generate a Unique Label }
function NewLabel: string;
var S: string;
begin
Str(LCount, S);
NewLabel := 'L' + S;
Inc(LCount);
end;
{ Post a Label To Output }
procedure PostLabel(L: string);
begin
WriteLn(L, ':');
end;
{ Output a String with Tab }
procedure Emit(s: string);
begin
Write(TAB, s);
end;
{ Output a String with Tab and CRLF }
procedure EmitLn(s: string);
begin
Emit(s);
WriteLn;
end;
{---------------------------------------------------------------}
{ Parse and Translate an Identifier }
procedure Ident;
var Name: char;
begin
Name := GetName;
if Look = '(' then begin
Match('(');
Match(')');
EmitLn('BSR ' + Name);
end
else
EmitLn('MOVE ' + Name + '(PC),D0');
end;
{---------------------------------------------------------------}
{ Parse and Translate a Math Factor }
procedure Expression; Forward;
procedure Factor;
begin
if Look = '(' then begin
Match('(');
Expression;
Match(')');
end
else if IsAlpha(Look) then
Ident
else
EmitLn('MOVE #' + GetNum + ',D0');
end;
{---------------------------------------------------------------}
{ Parse and Translate the First Math Factor }
procedure SignedFactor;
var s: boolean;
begin
s := Look = '-';
if IsAddop(Look) then begin
GetChar;
SkipWhite;
end;
Factor;
if s then
EmitLn('NEG D0');
end;
{ Recognize and Translate a Multiply }
procedure Multiply;
begin
Match('*');
Factor;
EmitLn('MULS (SP)+,D0');
end;
{-------------------------------------------------------------}
{ Recognize and Translate a Divide }
procedure Divide;
begin
Match('/');
Factor;
EmitLn('MOVE (SP)+,D1');
EmitLn('EXS.L D0');
EmitLn('DIVS D1,D0');
end;
{---------------------------------------------------------------}
{ Completion of Term Processing (called by Term and FirstTerm }
procedure Term1;
begin
while IsMulop(Look) do begin
EmitLn('MOVE D0,-(SP)');
case Look of
'*': Multiply;
'/': Divide;
end;
end;
end;
{---------------------------------------------------------------}
{ Parse and Translate a Math Term }
procedure Term;
begin
Factor;
Term1;
end;
{---------------------------------------------------------------}
{ Parse and Translate a Math Term with Possible Leading Sign }
procedure FirstTerm;
begin
SignedFactor;
Term1;
end;
{---------------------------------------------------------------}
{ Recognize and Translate an Add }
procedure Add;
begin
Match('+');
Term;
EmitLn('ADD (SP)+,D0');
end;
{---------------------------------------------------------------}
{ Recognize and Translate a Subtract }
procedure Subtract;
begin
Match('-');
Term;
EmitLn('SUB (SP)+,D0');
EmitLn('NEG D0');
end;
{---------------------------------------------------------------}
{ Parse and Translate an Expression }
procedure Expression;
begin
FirstTerm;
while IsAddop(Look) do begin
EmitLn('MOVE D0,-(SP)');
case Look of
'+': Add;
'-': Subtract;
end;
end;
end;
{---------------------------------------------------------------}
{ Parse and Translate a Boolean Condition }
{ This version is a dummy }
Procedure Condition;
begin
EmitLn('Condition');
end;
{---------------------------------------------------------------}
{ Recognize and Translate an IF Construct }
procedure Block;
Forward;
procedure DoIf;
var L1, L2: string;
begin
Match('i');
Condition;
L1 := NewLabel;
L2 := L1;
EmitLn('BEQ ' + L1);
Block;
if Look = 'l' then begin
Match('l');
L2 := NewLabel;
EmitLn('BRA ' + L2);
PostLabel(L1);
Block;
end;
PostLabel(L2);
Match('e');
end;
{ Parse and Translate an Assignment Statement }
procedure Assignment;
var Name: char;
begin
Name := GetName;
Match('=');
Expression;
EmitLn('LEA ' + Name + '(PC),A0');
EmitLn('MOVE D0,(A0)');
end;
{ Recognize and Translate a Statement Block }
procedure Block;
begin
while not(Look in ['e', 'l']) do begin
case Look of
'i': DoIf;
CR: while Look = CR do
Fin;
else Assignment;
end;
end;
end;
{ Parse and Translate a Program }
procedure DoProgram;
begin
Block;
if Look <> 'e' then Expected('END');
EmitLn('END')
end;
{ Initialize }
procedure Init;
begin
LCount := 0;
GetChar;
end;
{ Main Program }
begin
Init;
DoProgram;
end.
Пара комментариев:
| · | Форма синтаксического анализатора выражений, использующего FirstTerm и т.п., немного отличается от того, что вы видели ранее. Это еще одна вариация на ту же самую тему. Не позволяйте им вертеть вами... изменения необязательны для того, что будет дальше. |
| · | Заметьте, что как обычно я добавил вызовы Fin в стратегических местах для поддержки множественных строк. |
| · | Добавлены переменные Token и Value и определения типов, необходимые для Lookup. |
| · | Добавлено определение KWList и KWcode. |
| · | Добавлен Lookup. |
| · | GetName и GetNum заменены их много символьными версиями. (Обратите внимание, что вызов Lookup был перемещен из GetName, так что он не будет выполняться внутри выражений). |
| · | Создана новая, рудиментарная Scan, которая вызывает GetName затем сканирует ключевые слова. |
| · | Создана новая процедура MatchString, которая ищет конкретное ключевое слово. Заметьте, что в отличие от Match, MatchString не считывает следующее ключевое слово. |
| · | Изменен Block для вызова Scan. |
| · | Немного изменены вызовы Fin. Fin теперь вызывается из GetName. |
program KISS;
{ Constant Declarations }
const TAB = ^I;
CR = ^M;
LF = ^J;
{ Type Declarations }
type Symbol = string[8];
SymTab = array[1..1000] of Symbol;
TabPtr = ^SymTab;
{ Variable Declarations }
var Look : char; { Lookahead Character }
Token : char; { Encoded Token }
Value : string[16]; { Unencoded Token }
Lcount: integer; { Label Counter }
{ Definition of Keywords and Token Types }
const KWlist: array [1..4] of Symbol =
('IF', 'ELSE', 'ENDIF', 'END');
const KWcode: string[5] = 'xilee';
{ Read New Character From Input Stream }
procedure GetChar;
begin
Read(Look);
end;
{ Report an Error }
procedure Error(s: string);
begin
WriteLn;
WriteLn(^G, 'Error: ', s, '.');
end;
{ Report Error and Halt }
procedure Abort(s: string);
begin
Error(s);
Halt;
end;
{ Report What Was Expected }
procedure Expected(s: string);
begin
Abort(s + ' Expected');
end;
{ Recognize an Alpha Character }
function IsAlpha(c: char): boolean;
begin
IsAlpha := UpCase(c) in ['A'..'Z'];
end;
{ Recognize a Decimal Digit }
function IsDigit(c: char): boolean;
begin
IsDigit := c in ['0'..'9'];
end;
{ Recognize an AlphaNumeric Character }
function IsAlNum(c: char): boolean;
begin
IsAlNum := IsAlpha(c) or IsDigit(c);
end;
{ Recognize an Addop }
function IsAddop(c: char): boolean;
begin
IsAddop := c in ['+', '-'];
end;
{ Recognize a Mulop }
function IsMulop(c: char): boolean;
begin
IsMulop := c in ['*', '/'];
end;
{ Recognize White Space }
function IsWhite(c: char): boolean;
begin
IsWhite := c in [' ', TAB];
end;
{ Skip Over Leading White Space }
procedure SkipWhite;
begin
while IsWhite(Look) do
GetChar;
end;
{ Match a Specific Input Character }
procedure Match(x: char);
begin
if Look <> x then Expected('''' + x + '''');
GetChar;
SkipWhite;
end;
{ Skip a CRLF }
procedure Fin;
begin
if Look = CR then GetChar;
if Look = LF then GetChar;
SkipWhite;
end;
{ Table Lookup }
function Lookup(T: TabPtr; s: string; n: integer): integer;
var i: integer;
found: boolean;
begin
found := false;
i := n;
while (i > 0) and not found do
if s = T^[i] then
found := true
else
dec(i);
Lookup := i;
end;
{ Get an Identifier }
procedure GetName;
begin
while Look = CR do
Fin;
if not IsAlpha(Look) then Expected('Name');
Value := '';
while IsAlNum(Look) do begin
Value := Value + UpCase(Look);
GetChar;
end;
SkipWhite;
end;
{ Get a Number }
procedure GetNum;
begin
if not IsDigit(Look) then Expected('Integer');
Value := '';
while IsDigit(Look) do begin
Value := Value + Look;
GetChar;
end;
Token := '#';
SkipWhite;
end;
{ Get an Identifier and Scan it for Keywords }
procedure Scan;
begin
GetName;
Token := KWcode[Lookup(Addr(KWlist), Value, 4) + 1];
end;
{ Match a Specific Input String }
procedure MatchString(x: string);
begin
if Value <> x then Expected('''' + x + '''');
end;
{ Generate a Unique Label }
function NewLabel: string;
var S: string;
begin
Str(LCount, S);
NewLabel := 'L' + S;
Inc(LCount);
end;
{ Post a Label To Output }
procedure PostLabel(L: string);
begin
WriteLn(L, ':');
end;
{ Output a String with Tab }
procedure Emit(s: string);
begin
Write(TAB, s);
end;
{ Output a String with Tab and CRLF }
procedure EmitLn(s: string);
begin
Emit(s);
WriteLn;
end;
{---------------------------------------------------------------}
{ Parse and Translate an Identifier }
procedure Ident;
begin
GetName;
if Look = '(' then begin
Match('(');
Match(')');
EmitLn('BSR ' + Value);
end
else
EmitLn('MOVE ' + Value + '(PC),D0');
end;
{---------------------------------------------------------------}
{ Parse and Translate a Math Factor }
procedure Expression; Forward;
procedure Factor;
begin
if Look = '(' then begin
Match('(');
Expression;
Match(')');
end
else if IsAlpha(Look) then
Ident
else begin
GetNum;
EmitLn('MOVE #' + Value + ',D0');
end;
end;
{---------------------------------------------------------------}
{ Parse and Translate the First Math Factor }
procedure SignedFactor;
var s: boolean;
begin
s := Look = '-';
if IsAddop(Look) then begin
GetChar;
SkipWhite;
end;
Factor;
if s then
EmitLn('NEG D0');
end;
{ Recognize and Translate a Multiply }
procedure Multiply;
begin
Match('*');
Factor;
EmitLn('MULS (SP)+,D0');
end;
{-------------------------------------------------------------}
{ Recognize and Translate a Divide }
procedure Divide;
begin
Match('/');
Factor;
EmitLn('MOVE (SP)+,D1');
EmitLn('EXS.L D0');
EmitLn('DIVS D1,D0');
end;
{---------------------------------------------------------------}
{ Completion of Term Processing (called by Term and FirstTerm }
procedure Term1;
begin
while IsMulop(Look) do begin
EmitLn('MOVE D0,-(SP)');
case Look of
'*': Multiply;
'/': Divide;
end;
end;
end;
{---------------------------------------------------------------}
{ Parse and Translate a Math Term }
procedure Term;
begin
Factor;
Term1;
end;
{---------------------------------------------------------------}
{ Parse and Translate a Math Term with Possible Leading Sign }
procedure FirstTerm;
begin
SignedFactor;
Term1;
end;
{---------------------------------------------------------------}
{ Recognize and Translate an Add }
procedure Add;
begin
Match('+');
Term;
EmitLn('ADD (SP)+,D0');
end;
{---------------------------------------------------------------}
{ Recognize and Translate a Subtract }
procedure Subtract;
begin
Match('-');
Term;
EmitLn('SUB (SP)+,D0');
EmitLn('NEG D0');
end;
{---------------------------------------------------------------}
{ Parse and Translate an Expression }
procedure Expression;
begin
FirstTerm;
while IsAddop(Look) do begin
EmitLn('MOVE D0,-(SP)');
case Look of
'+': Add;
'-': Subtract;
end;
end;
end;
{---------------------------------------------------------------}
{ Parse and Translate a Boolean Condition }
{ This version is a dummy }
Procedure Condition;
begin
EmitLn('Condition');
end;
{---------------------------------------------------------------}
{ Recognize and Translate an IF Construct }
procedure Block; Forward;
procedure DoIf;
var L1, L2: string;
begin
Condition;
L1 := NewLabel;
L2 := L1;
EmitLn('BEQ ' + L1);
Block;
if Token = 'l' then begin
L2 := NewLabel;
EmitLn('BRA ' + L2);
PostLabel(L1);
Block;
end;
PostLabel(L2);
MatchString('ENDIF');
end;
{ Parse and Translate an Assignment Statement }
procedure Assignment;
var Name: string;
begin
Name := Value;
Match('=');
Expression;
EmitLn('LEA ' + Name + '(PC),A0');
EmitLn('MOVE D0,(A0)');
end;
{ Recognize and Translate a Statement Block }
procedure Block;
begin
Scan;
while not (Token in ['e', 'l']) do begin
case Token of
'i': DoIf;
else Assignment;
end;
Scan;
end;
end;
{ Parse and Translate a Program }
procedure DoProgram;
begin
Block;
MatchString('END');
EmitLn('END')
end;
{ Initialize }
procedure Init;
begin
LCount := 0;
GetChar;
end;
{ Main Program }
begin
Init;
DoProgram;
end.
Сравните эту программу с ее одно-символьным вариантом. Я думаю вы согласитесь, что различия минимальны.
ЗАКЛЮЧЕНИЕ
К этому времени вы узнали как анализировать и генерировать код для выражений, булевых выражений и управляющих структур. Теперь вы изучили, как разрабатывать лексические анализаторы и как встроить их элементы в транслятор. Вы все еще не видели всех элементов, объединенных в одну программу, но на основе того, что мы сделали ранее вы должны прийти к заключению, что легко расширить наши ранние программы для включения лексических анализаторов.
Мы очень близки к получению всех элементов, необходимых для построения настоящего, функционального компилятора. Есть еще несколько отсутствующих вещей, особенно вызовы процедур и определения типов. Мы будем работать с ними на следующих нескольких уроках. Прежде чем сделать это, однако, я подумал что было бы забавно превратить транслятор в настоящий компилятор. Это то, чем мы займемся в следующей главе.
До настоящего времени мы применяли предпочтительно восходящий метод синтаксического анализа, начиная с низкоуровневых конструкций и продвигаясь вверх. В следующей главе я также взгляну сверху вниз, и мы обсудим, как изменяется структура транслятора при изменении определения языка.